Doc-RAG MultiTenant Processor
Automates secure, per-client RAG document processing and search
Trusted by
Built with OpenAI, Supabase pgvector, and LangChain—industry-trusted technologies used in thousands of enterprise RAG deployments.
Success Story
Great American Insurance achieved 5× faster submission processing and 90% shorter review cycles using a comparable AI document-processing pipeline.
Integrates with
Problem
Businesses offering document-based insights struggle to manage multiple clients’ data securely. Building a retrieval-augmented generation (RAG) pipeline that keeps each client’s data isolated, continuously updated, and instantly searchable requires complex engineering and infrastructure management.
Solution
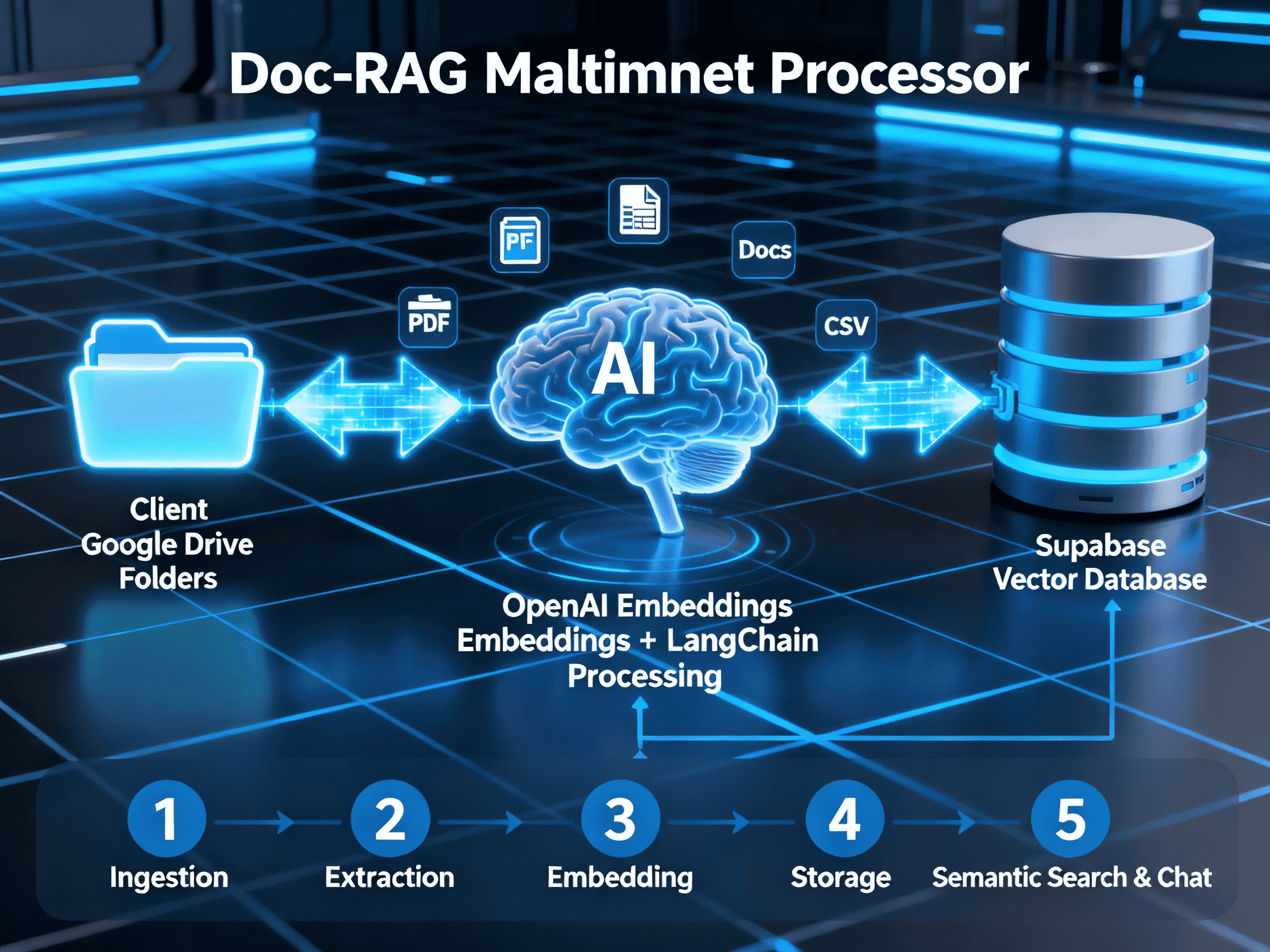
Doc- RAG MultiTenant Processor provides an end-to-end automated pipeline that handles ingestion, cleaning, and vectorization of documents per client. It automatically creates client-specific vector databases, processes all document types, and maintains real-time updates between cloud storage and the vector store. Each tenant’s data remains completely isolated, ensuring security and compliance while enabling semantic search, contextual QA, and AI-powered retrieval over their documents.
Result
Businesses can deploy per-client RAG environments in hours instead of weeks. Data ingestion latency is reduced from hours to minutes, and search responses remain under 200 ms with high semantic accuracy.
Use Cases
Doc-RAG MultiTenant Processor automates the entire lifecycle of client document ingestion, processing, and retrieval. It continuously monitors designated client folders in Google Drive, extracts and processes files in multiple formats (PDF, Google Docs, Excel, CSV), generates semantic embeddings using OpenAI models, and stores them in client-isolated vector tables in Supabase. This architecture ensures complete tenant data separation, real-time updates, and instant readiness for semantic search or chat-based document retrieval. By automating ingestion and embedding, organizations can provide their clients with personalized, secure RAG environments in minutes rather than weeks. This solution eliminates manual data preparation, schema management, and index maintenance while maintaining strict data isolation and compliance.
Integrations
Connect to your existing tools seamlessly
Technology Stack
Automation
Automation
Infrastructure
Implementation Timeline
Platform & Infrastructure Setup
5–7 daysSupabase account configuration, database creation with pgvector extension, API key setup, and initial connection to OpenAI embeddings. Google Drive folder monitoring is activated for each client, and secure credential storage is tested.
Pipeline Configuration & Automation
10–14 daysWorkflow nodes configured for document ingestion, file-type routing, text extraction, and embedding generation. Client-specific table automation is implemented, and data isolation between tenants is validated. Integration of LangChain components for text splitting, metadata tagging, and vector insertion into Supabase.
esting, Optimization & Launch
5–7 daysEnd- to-end validation of document ingestion, embedding accuracy, and vector search response times. Latency optimization for semantic queries, monitoring setup, and client onboarding documentation. Rollout to production with sample tenant environments.
Support Included
Complete setup documentation, node configuration templates, and API integration guides for Supabase, OpenAI, and Google Drive. Includes troubleshooting checklist, performance tuning guidelines, and optional consulting support for enterprise deployment.
More from Customer Support
Popular agents in this category
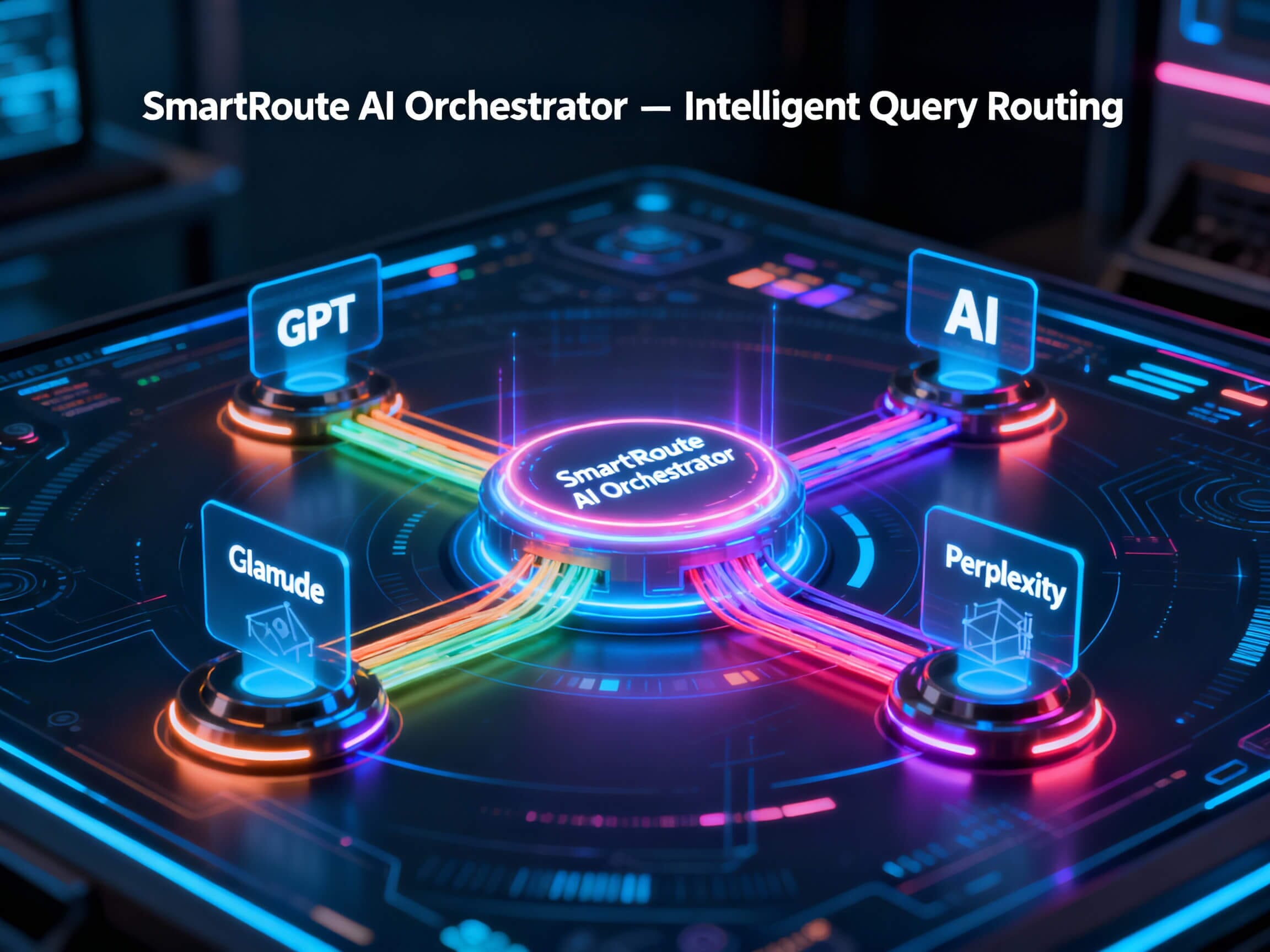
SmartRoute AI Orchestrator
Salesforce saved 50,000 hours in one quarter using Einstein in Slack to automate routine tasks
Automatically routes user queries to the optimal AI model (GPT, Claude, Gemini, Perplexity)

SupportLoop Auto-Responder
Allstate shifted most of 50k daily claimant communications to AI-written, human-verified emails—clearer, less jargony responses
Answer support emails automatically, learn from experts, and improve every day
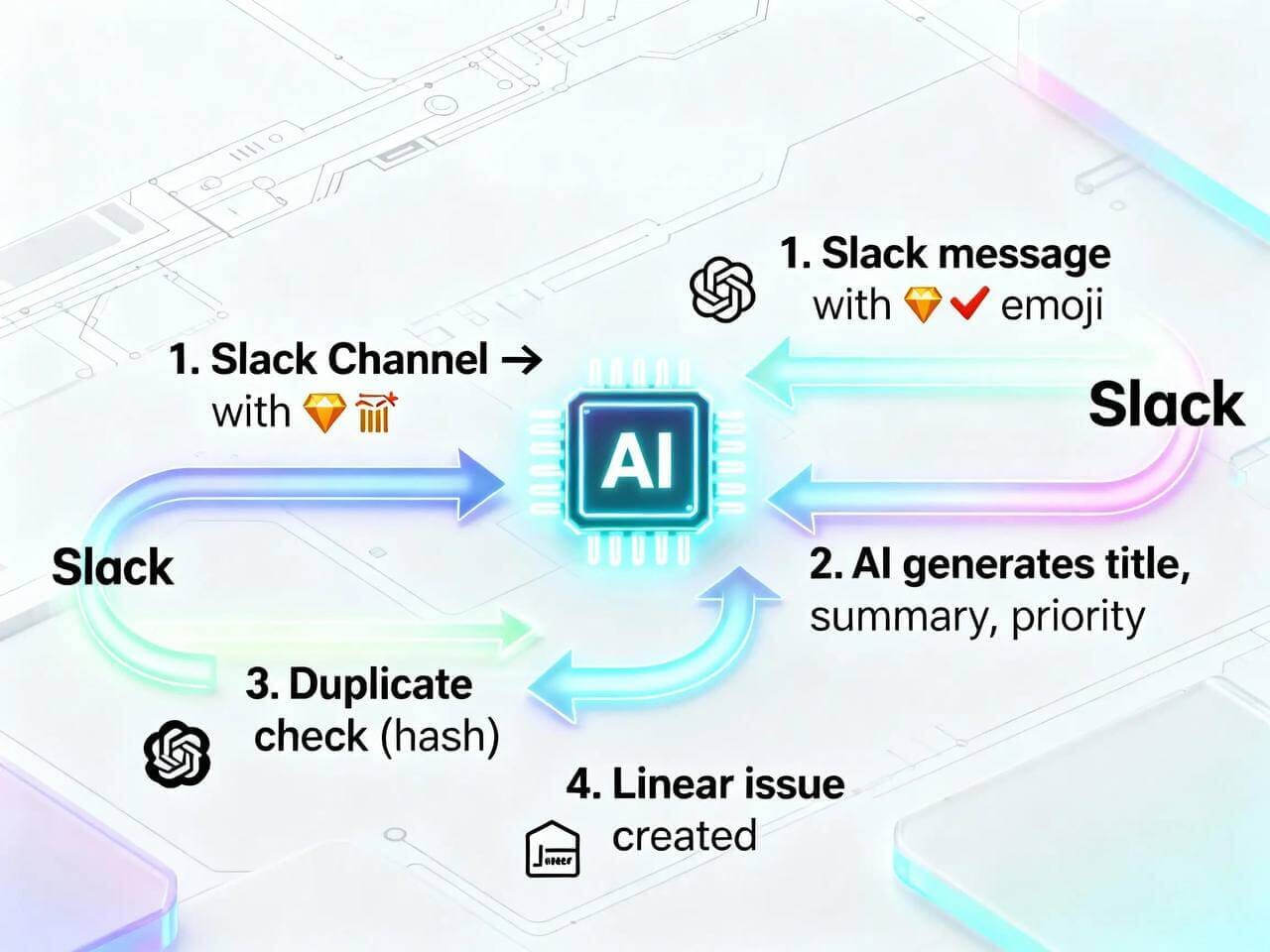
Support Triage Router
Slack cut ticket response from ~2 days to 24 hours, with 97% tickets submitted via Slack using Halp workflows
Turn Slack messages into prioritized Linear tickets—auto, clean, deduplicated

Agentic Telegram AI Bot
OPPO achieved an 83% chatbot resolution rate and a 57% boost in repurchase rates with Sobot’s AI-powered customer service solutions.
Enhance customer support with an intelligent Telegram bot that leverages LangChain and OpenAI

24/7 AI Chatbot
"Intercom reduced average response time from 24 hours to 2 minutes, improving customer satisfaction by 20% using AI chatbots." Example of similar AI customer support solution, not this specific agent
Provides instant, accurate customer support around the clock.

ChatOps WhatsApp Concierge
Klarna’s AI assistant handled 2/3 of customer chats and cut repeat contacts by 25% in its first month
Turn WhatsApp into a smart assistant with memory, research, and Google Suite actions

ContextKeeper Chat Assistant
*Klarna AI assistant handled 2.3 million conversations in first month, doing the equivalent of 700 full-time agents, reducing resolution from ~11 mins to ~2 mins
Persistent chat memory + instant answers, right in your chat UI

DriveWatch AI — Google Drive Change Monitor
Kloudless used their unified Events API to detect Drive changes reliably across users, enabling sync workloads to detect thousands of file changes per minute
Continuously monitors nested Google Drive folders and reports new or modified files automatically